
티스토리 뷰
2020/10/24 - [Study/인공지능] - Optimizer : AdaGrad, RMSprop ( 인공지능 기초 # 15 )
Momentum과 RMSProp 두가지 방식을 합쳐 놓은 옵티마이저 입니다.
따라서 복잡하지만, 현재 가장 많이 쓰이는 옵티마이저 입니다.
가중치 B1으로 Momentum을 변형하여 점화식 [직전의 속도값 고려 (관성고려)]

을 생각하고 가중치 B2로 AdaGrad를 변형하여 점화식
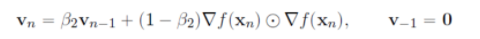
을 생각합니다.
베타1과 베타2는 일반적으로 0.9나 0.99와 같은 1에 굉장히 가까운 숫자로 둡니다.
이때문에 초기값이 0인것에 영향을 받아 0에 편향된다. 그래서 이를 보정작업을 실시합니다.
m은 관성과 그레디언트를 내분한 것


매우 복잡하다..
복잡하긴 한데, ./././ 각 장점을 섞어놓은 것이다..
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)
'Study > 인공지능' 카테고리의 다른 글
| Xavier/He 초기값 ( 인공지능 기초 # 18 ) (0) | 2020.10.26 |
|---|---|
| optimizer 종합 banch mark ( 인공지능 기초 # 17) (0) | 2020.10.25 |
| Optimizer : AdaGrad, RMSprop ( 인공지능 기초 # 15 ) (0) | 2020.10.24 |
| Optimizer : Momentum, NAG ( 인공지능 기초 #14 ) (0) | 2020.10.23 |
| Optimizer: SGD ( 인공지능 기초 #13 ) (0) | 2020.10.22 |
댓글